MongoDB Performance Fundamentals: Indexing & Indexes
9 minute read
I originally wrote this post to appear on the FloQast Engineering Blog.
I know how frustrating slow apps are. I also really care about my users’ time. One of the best ways to respect peoples’ time when using your applications is by ensuring your database is humming smoothly. I’ve learned how to work with MongoDB over the years in order to make sure my users’ time isn’t wasted and wanted to share some of those lessons here. In this post, we’ll start by learning about one of the most important concepts & tools available to you in MongoDB: indexes.
Database Performance
Database design and performance is a complex field. You have to think about consistency, availability, how well it handles network partitions… and to cap it all off the database has to be easy to use and run. So let’s boil it down to a few basic questions:
- “How fast can I read something?”
- “How fast can I update something?”
- “How reliable is my read/write?”
- “How durable is my update?” In this post, we’ll focus on question #1: how fast can I read data?
How Fast Can I Read Something?
You’ll probably encounter slowdowns on database reads before you encounter slowdowns in inserts or updates. That’s because many common database use-cases are proportionally read-heavy as opposed to write-heavy. Many databases will “just work” at small to even medium-scale without any additional tuning or effort. Most databases have been developed for 10+ years now and modern hardware is usually more than sufficient for many needs.
This really changes when you add more X. X can be volume, data size, read frequency, write frequency — whatever. When you start to scale your database, you’re going to need to do some work to make sure it performs as expected. When a product is smaller and getting less traffic or usage, we can use MongoDB out-of-the-box without doing any tuning. Mongo has great internal caching mechanisms and is pretty speedy in general. But as things grow and you add more features, users, and increas in overall volume, you have to take steps to ensure our users can close the books quickly and efficiently.
The first thing to do when scaling your database is to understand your data model and data access patterns. If you don’t have those down, scaling will be frustratingly-difficult or impossible. We’ve had to index and reindex our databases many times over the years as workloads have shifted and our needs have evolved.
In this post, we’ll take a look at some basic techniques
you can use to improve the performance of your MongoDB
database. To illustrate, let’s imagine a fictional
service focusing on driverless-cars and ride-sharing:
SomeCars. SomeCars is a very read-heavy
application and has started to slow down, so we need to
figure out how to improve performance. Below is an
example schema for a riderin the SomeCars
system. A few things to note:
-
the schema employs denormalization; there are
ridesembedded in theridermodel as an array of subdocuments - user geolocation info is stored as lat/lng coordinates
- some key info (email, ID, name) is also stored in the document
{
"_id": "5cf0029caff5056591b0ce7d",
"name": "A. Person",
"email": "[email protected]",
"avatarURL": "https://static.image.com/1234",
"password": "$2a$14$ajq8Q7fbtFRQvXpdCq7Jcuy.Rx1h/L4J60Otx.gyNLbAYctGMJ9tK",
"rides": [
{
"_id": "5cf0029caff5056591b0ce2f",
"date": "01/01/2006",
"driverID": "5cf0029caff5056591b0ce20",
"from": {
"lat": -70.55044,
"lng": 165.39229
},
"to": {
"lat": -29.9244,
"lng": 88.2593
}
},
{
"_id": "5cf0029caff5056591b0ce2a",
"date": "01/02/2006",
"from": {
"lat": -70.55044,
"lng": 165.39229
},
"to": {
"lat": -29.9244,
"lng": 88.2593
}
}
],
"location": {
"current": {
"lat": -70.55044,
"lng": 165.39229
}
}
}
For this series, we’ve spun up a demo MongoDB cluster and populated with around 1.2 million rider documents, all randomly-generated. We’ll use this schema and data in the examples below.
Indexes to the rescue!
SomeCars users have reported slow in-app experiences to our awesome support team and HTTP response times are looking a lot higher in our Grafana metrics dashboard. So we definitely need to make some changes to our database and quickly! What to do? We already know our data model and data access patterns. What’s next? Indexes to the rescue!

live look at indexes coming in to help us destroy slowness
What’s an index? In database terms, an index is a data structure that improves the speed of data access, but at a small cost. In our data-heavy world, most every database has an indexing strategy and it’s usually an important part of the database’s overall feature-set. If you haven’t heard of indexes before, you’ve probably seen them in real life. Flip to the back of a book and it’ll probably have an index of where terms or topics appear in the book. Indexes used by databases are actually very similar. They provide a faster way for the database to look for items in a query, much the same as you might quickly scan the index to see where a term appears before exhaustively searching the book.
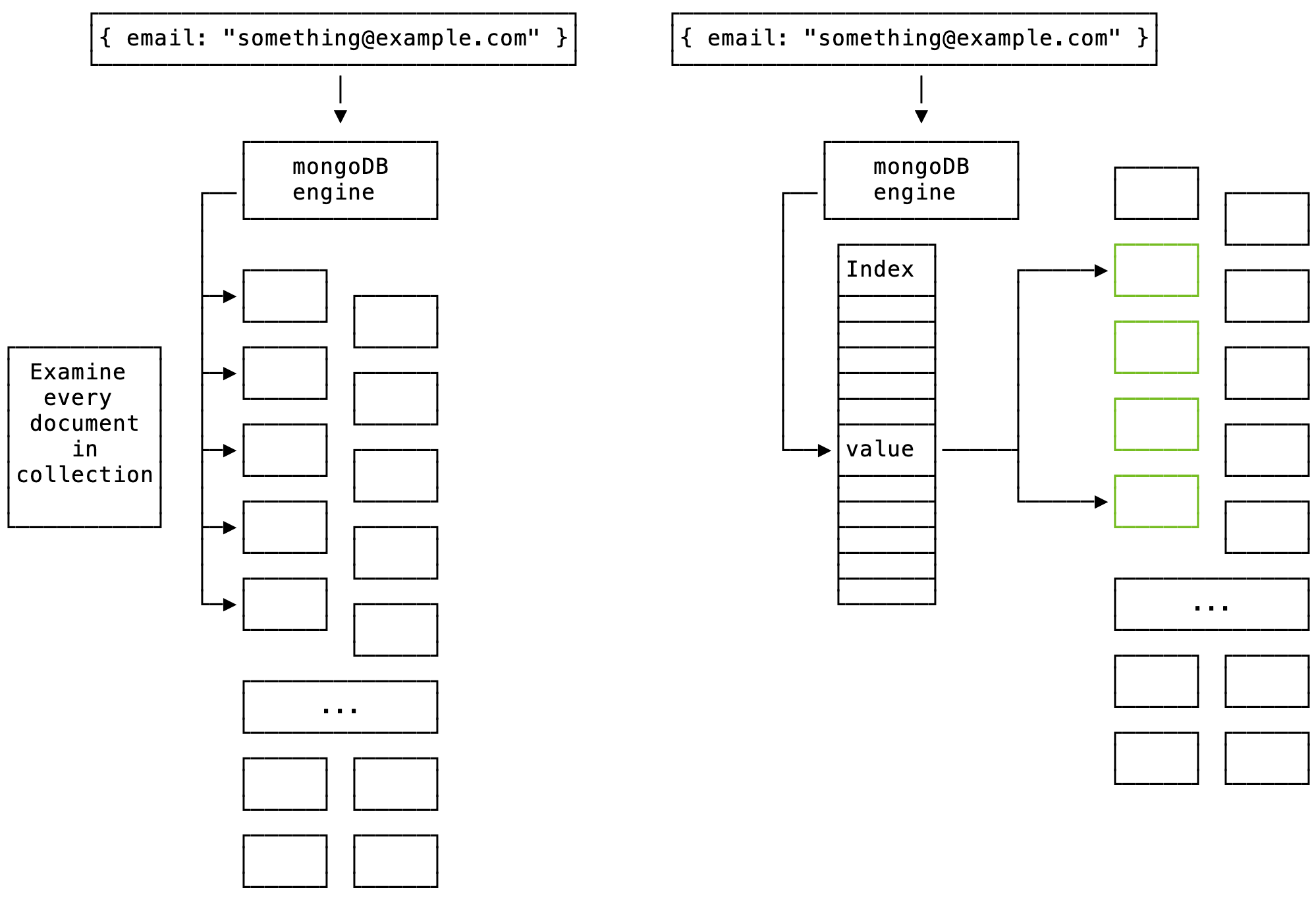
An index in action. Without an index, MongoDB must examine every document in order to fulfill a query. With an index, however, it can very quickly narrow down what it’s looking for.
Common MongoDB index types include:
- Single: indexes on a single field (e.g. “email”)
- Multikey: indexes for fields that hold an array value
- Compound: indexes on multiple fields in a document
Single-field
There’s a SomeCars feature that does lookups on users using their email address, and we’ve noticed it’s slow (from our users and our dashboards). Let’s do a sample query to find an email we already know exists:
db.riders.findOne({ email: "Odessa [email protected]" });
This is a direct lookup and should be fast, especially since we actually know what we’re looking for in the database. However, the execution statistics show otherwise:
- Documents Returned: 1
- Index Keys Examined: 0
- Documents Examined: 1188100
- Actual Query Execution Time: 667ms
🤔🤔🤔Notice that we looked at every item in the database, leading to the 667ms query time. This might not seem like a long time, but it’s an eternity in database terms. Our users will definitely be frustrated by services that have to use this query. Let’s fix it with a single-field index:
db.riders.createIndex({ email: 1 }, { background: true });
We’re creating an index on the email field and
we’ve done it in the background so we don’t
disrupt running production systems (remember how
important our users’ time is?). Creating indexes in the
background takes longer but is worth the wait. Did you
also notice how we set the index sort direction as
ascending (going up):1? This won’t matter
as much for single-field indexes but will be crucial for
compound indexes.
After adding the index, let’s run the same query again:
db.riders.findOne({ email: "Odessa [email protected]" });
- Documents Returned: 1
- Index Keys Examined: 1
- Documents Examined: 1
- Actual Query Execution Time: 2ms
Much better!
Unique Indexes
The index we just created isn’t just going to help with
performance. If we drop and recreate the index with the
unique option, MongoDB will prevent inserts
of documents with duplicate fields. Most index types in
MongoDB can be unique. For example:
db.riders.createIndex({ email: 1 }, { background: true, unique: true });
This is a great way to do uniqueness checks really quickly and adds additional safeguards against duplicate data that can cause hard-to-resolve bugs or security vulnerabilities.
Multikey
Now that we’ve improved the performance of that query, we get another report from our users: queries that show rides taken with a particular self-driving car ID are taking a long time to load. The query looks something like the following:
db.riders.findOne({ "rides.driverID": ObjectId("5dee0e1467adb71ef2362050") });
The query performance is even worse than our first example due to having to also having to search through an array for a value:
- Documents Returned: 1
- Index Keys Examined: 0
- Documents Examined: 1188100
- Actual Query Execution Time: 1854ms
We are once again examining every document in the collection (a “collection scan”), which is a worst-case scenario. Let’s add an index to the driverID field in the rides array:
db.riders.createIndex({ "rides.driverID": 1 }, { background: true });
After creating a single-field multikey index, let’s see what our performance is like:
- Documents Returned: 1
- Index Keys Examined: 1
- Documents Examined: 1
- Actual Query Execution Time: 1ms
Much faster! Because we created a single-field index on
an array item, MongoDB created an index entry for each
item in the array. This is, in part, why we see
nearly-identical performance between this and the
email query. Multikey indexes have a few
nuances to them, however, and
the MongoDB documentation
does a great job of covering any quirks.
Compound
Having solved our email and
riderID queries, we find - yet again - that
we have a poorly-performing query: an admin portion of
the SomeCars app shows support users a view of rides
taken within a time-range, sorted alphabetically by
email so it’s easier to view in-app. The query
looks something like this:
db.riders
.find({
"rides.date": {
$lte: ISODate("12/01/2019"),
$gte: ISODate("11/01/2019"),
},
})
.sort({ email: -1 });
As expected, our query is examining a huge number of documents in order to return
- Documents Returned: 1068298
- Index Keys Examined: 1188100
- Documents Examined: 1188100
- Actual Query Execution Time: 3901ms
This is where compound indexes really come in handy. You may have been thinking to yourself earlier “But what if I’m not doing something as simple as looking up by email?” Compound indexes are often what you’d be looking for. They allow the creation of indexes using multiple keys in a particular order to improve both lookup and sort ordering. Whereas single-field indexes are traversable in either direction by MongoDB, you have to carefully think about index sort-order for compound indexes.
MongoDB will create a compound index using the order and
sort-direction of fields you specify. This means
you’ll want to think about not only the data
you’re accessing (e.g., “email”, but
the “when” of the data (how far will MongoDB
have to scan to get to a document?) and how you are
sorting that data. For our case, we want to as quickly
as possible and narrow down the possible users’
email addresses to avoid doing a global sort of all user
emails. We can use the rides.date field for
this and set a descending sort direction. We will also
specify an ascending sort order for the email field
since our support users will be going forward
alphabetically.
db.riders.createIndex({ "rides.date": -1, email: 1 }, { background: true });
Huzzah! The fields of our documents are working together and things are much faster. We’re still examining a good number of documents, but they are all within the time range specified, so we might not be able to do much better given our range-based query.
- Documents Returned: 6703
- Index Keys Examined: 6795
- Documents Examined: 6771
- Actual Query Execution Time: 143ms
What’s next?
Now you have a handful of tools to improve your queries in MongoDB using several kinds of indexes. Hopefully these cover most of your typical use-cases - they have for me. MongoDB also has index types to handle textual data for full-text-search applications and geographic queries for location-based data types.